一、Prometheus监控配置与MinIO指标采集
1.1 先决条件:
- 一个现有的 Prometheus 部署,并支持告警
- 一个现有的 MinIO 部署,并具有对 Prometheus 部署的网络访问权限
- 本地主机上安装了
mc,并已配置可访问 MinIO
1.2 使用mc命令生成抓取配置
使用 mc admin prometheus generate 命令生成抓取配置,供 Prometheus 用于发出抓取请求1.2.1 抓取 MinIO 集群的指标
以下命令抓取 MinIO 集群的指标。将 ALIAS 替换为 MinIO 部署的 别名。
mc admin prometheus generate ALIAS该命令返回类似于以下内容的输出:
global:
scrape_interval: 60s
scrape_configs:
- job_name: minio-job
bearer_token: TOKEN
metrics_path: /minio/v2/metrics/cluster
scheme: https
static_configs:
- targets: [minio.example.net]1.2.2 抓取 MinIO 服务器上某个节点的指标
以下命令抓取 MinIO 服务器上某个节点的指标。将 ALIAS 替换为 MinIO 部署的 别名。
mc admin prometheus generate ALIAS node该命令返回类似于以下内容的输出:
global:
scrape_interval: 60s
scrape_configs:
- job_name: minio-job-node
bearer_token: TOKEN
metrics_path: /minio/v2/metrics/node
scheme: https
static_configs:
- targets: [minio-1.example.net, minio-2.example.net, minio-N.example.net]1.2.3 抓取 MinIO 服务器上存储桶的指标
以下命令抓取 MinIO 服务器上存储桶的指标。将 ALIAS 替换为 MinIO 部署的 别名。
mc admin prometheus generate ALIAS bucket该命令返回类似于以下内容的输出:
global:
scrape_interval: 60s
scrape_configs:
- job_name: minio-job-bucket
bearer_token: TOKEN
metrics_path: /minio/v2/metrics/bucket
scheme: https
static_configs:
- targets: [minio.example.net]1.2.4 抓取 MinIO 服务器上资源的指标。
以下命令抓取 MinIO 服务器上资源的指标。将 ALIAS 替换为 MinIO 部署的 别名。
⚠️:版本 RELEASE.2023-10-07T15-07-38Z 中的新增功能。
mc admin prometheus generate ALIAS resource该命令返回类似于以下内容的输出:
global:
scrape_interval: 60s
scrape_configs:
- job_name: minio-job-resource
bearer_token: TOKEN
metrics_path: /minio/v2/metrics/resource
scheme: https
static_configs:
- targets: [minio.example.net]1.2.5 配置抓取注意事项
- 设置适当的 scrape_interval 值以确保每个抓取操作在下一个操作开始之前完成。建议的值为 60 秒。由于要抓取的指标数量,某些部署需要更长的抓取间隔。为了减少 MinIO 和 Prometheus 服务器的负载,请选择满足监控要求的最长间隔。
- 将 job_name 设置为与 MinIO 部署关联的值。使用唯一值以确保部署指标与该 Prometheus 服务收集的任何其他指标隔离。
- 如果 MINIO_PROMETHEUS_AUTH_TYPE 设置为 "public",则可以省略 bearer_token 字段。
- 对于不使用 TLS 的 MinIO 部署,请将 scheme 设置为 http。
- 使用解析到 MinIO 部署的主机名设置 targets 数组。这可以是任何单个节点,或处理到 MinIO 节点连接的负载均衡器/代理。对于与 MinIO 租户位于同一集群中的 Prometheus 部署,您可以为 minio 服务指定服务 DNS 名称。对于集群外部的 Prometheus 部署,必须指定一个配置为路由 MinIO 租户之间连接的入口或负载均衡器端点。
1.3 使用更新的配置重新启动 Prometheus
1.3.1 将上一步生成的所需 scrape_configs 作业附加到配置文件中
- 我这里提供一个聚合好的配置文件:
global:
scrape_interval: 25s
scrape_configs:
- job_name: 'srebro-prod-minio'
scrape_interval: 60s # 每 60秒采集一次
bearer_token: xxxxxx
metrics_path: /minio/v2/metrics/cluster
scheme: http
static_configs:
- targets: ['127.0.0.1:9000']
labels:
tsingyun_project_name: "srebro-prod"
nodename: "运维小弟-生产-minio-单节点-192.168.3.110"
type: "minio-job"
- job_name: 'srebro-prod-minio-node'
scrape_interval: 60s # 每 60秒采集一次
bearer_token: xxxxxx
metrics_path: /minio/v2/metrics/node
scheme: http
static_configs:
- targets: ['127.0.0.1:9000']
labels:
tsingyun_project_name: "srebro-prod"
nodename: "运维小弟-生产-minio-单节点-192.168.3.110"
type: "minio-node"
- job_name: 'srebro-prod-minio-bucket'
scrape_interval: 60s # 每 60秒采集一次
bearer_token: xxxxxx
metrics_path: /minio/v2/metrics/bucket
scheme: http
static_configs:
- targets: ['127.0.0.1:9000']
labels:
tsingyun_project_name: "srebro-prod"
nodename: "运维小弟-生产-minio-单节点-192.168.3.110"
type: "minio-bucket"
- job_name: 'srebro-prod-minio-resource'
scrape_interval: 60s # 每 60秒采集一次
bearer_token: xxxxxx
metrics_path: /minio/v2/metrics/resource
scheme: http
static_configs:
- targets: ['127.0.0.1:9000']
labels:
tsingyun_project_name: "srebro-prod"
nodename: "运维小弟-生产-minio-单节点-192.168.3.110"
type: "minio-resource"1.3.2 检查配置文件是否正确
./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: prometheus.yml is valid prometheus config file syntax1.3.3 重新加载 prometheus 服务
curl -X POST http://127.0.0.1:9090/-/reload1.3.4 观察 prometheus 中的 Targets 情况

1.3.5 查看收集的指标
- 以下查询示例返回 Prometheus 每五分钟为名为
srebro-prod-minio-node的抓取作业收集的指标
minio_node_drive_free_bytes{job="srebro-prod-minio-node"}[5m]
minio_node_drive_free_inodes{job="srebro-prod-minio-node"}[5m]
minio_node_drive_latency_us{job="srebro-prod-minio-node"}[5m]
minio_node_drive_offline_total{job="srebro-prod-minio-node"}[5m]
minio_node_drive_online_total{job="srebro-prod-minio-node"}[5m]
minio_node_drive_total{job="srebro-prod-minio-node"}[5m]
minio_node_drive_total_bytes{job="srebro-prod-minio-node"}[5m]
minio_node_drive_used_bytes{job="srebro-prod-minio-node"}[5m]
minio_node_drive_errors_timeout{job="srebro-prod-minio-node"}[5m]
minio_node_drive_errors_availability{job="srebro-prod-minio-node"}[5m]
minio_node_drive_io_waiting{job="srebro-prod-minio-node"}[5m]1.3.6 MinIO 推荐的指标作为基本监控集。
| 指标 | 描述 |
|---|---|
minio_node_drive_free_bytes | 驱动器上可用的总存储空间。 |
minio_node_drive_free_inodes | 空闲 inode 总数。 |
minio_node_drive_latency_us | 驱动器 API 存储操作的平均最近一分钟延迟(以微秒为单位)。 |
minio_node_drive_offline_total | 此节点中脱机的驱动器总数。 |
minio_node_drive_online_total | 此节点中联机的驱动器总数。 |
minio_node_drive_total | 此节点中的驱动器总数。 |
minio_node_drive_total_bytes | 驱动器上的总存储空间。 |
minio_node_drive_used_bytes | 驱动器上使用的总存储空间。 |
minio_node_drive_errors_timeout | 自服务器启动以来驱动器超时错误的总数。 |
minio_node_drive_errors_availability | 自服务器启动以来驱动器 I/O 错误、权限被拒绝和超时的总数。 |
minio_node_drive_io_waiting | 等待驱动器 I/O 操作的总数。 |
1.4 使用 MinIO 指标配置警报规则
- 检测过去5分钟内是否存在离线状态的MinIO节点,若存在则触发告警
avg_over_time(minio_cluster_nodes_offline_total{job="srebro-prod-minio-node"}[5m]) > 0- 检测过去5分钟内MinIO集群中存在离线磁盘,若存在则触发告警
avg_over_time(minio_cluster_drive_offline_total{job="srebro-prod-minio-node"}[5m]) > 01.5 MinIO 健康检查 API
- MinIO 公开了未经身份验证的端点,用于探测节点正常运行时间和集群高可用性,以进行简单的健康检查。这些端点返回一个 HTTP 状态代码,指示基础资源是否健康或是否满足读取/写入仲裁。MinIO 不会通过这些端点公开任何其他数据。
- 仅靠健康检查探测无法确定 MinIO 服务器是否脱机,只能确定当前主机是否可以访问服务器。可搭配👆上面提到的
minio_cluster_nodes_offline_total指标配置 Prometheus 警报,以检测一个或多个 MinIO 节点是否脱机。
1.5.1 节点存活性
使用以下端点测试 MinIO 服务器是否在线
curl -I https://minio.example.net:9000/minio/health/live将 https://minio.example.net:9000 替换为要检查的 MinIO 服务器的 DNS 主机名。响应代码 200 OK 表示 MinIO 服务器在线且功能正常。任何其他 HTTP 代码都表示在访问服务器时出现问题,例如瞬态网络问题或潜在的停机时间。
1.5.2 使用 Node Exporter textfile 自定义指标收集器
- 前提: 需要先部署好
node-exporter监控组件。 - 通过获取这个接口的状态,将自定义的指标数据 写入文本文件。
- 定义脚本,获取每次接口的健康状态。
[root@localhost logs]# cat /home/application/prometheus/minio-health-check.sh
ENDPOINT="http://192.168.3.110:9000/minio/health/live"
STATUS_FILE="/home/application/prometheus/textfile_collector/minio_health.prom"
# 检查健康状态
if curl -f -s -o /dev/null --max-time 5 "$ENDPOINT"; then
echo "minio_health_check{endpoint=\"$ENDPOINT\"} 1" > "$STATUS_FILE"
else
echo "minio_health_check{endpoint=\"$ENDPOINT\"} 0" > "$STATUS_FILE"
fi- 提前创建好minio_health.prom 文件。
touch /home/application/prometheus/textfile_collector/minio_health.prom- 配置定时任务; 每 30秒执行一次。
crontab -e
#minio-health-check
* * * * * /home/application/prometheus/minio-health-check.sh
* * * * * sleep 30; /home/application/prometheus/minio-health-check.sh- 查看minio_health.prom 文件文件数据
minio_health_check{endpoint="http://192.168.3.110:9000/minio/health/live"} 1- 配置 node-exporter 采集器,指定 textfile 目录
[root@localhost logs]# cat /etc/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/home/application/node_exporter/node_exporter --collector.systemd --collector.textfile --collector.textfile.directory=/home/application/prometheus/textfile_collector
Restart=on-failure
[Install]
WantedBy=multi-user.target- 重新加载,并重启
systemctl daemon-reload
systemctl restart node_exporter- 配置 Prometheus 抓取数据 (新增 textfile 收集器)
scrape_configs:
- job_name: 'srebro-prod-linux'
params:
collect[]:
- textfile #新增 textfile 收集器
- cpu
- meminfo
- diskstats
- netdev
- netstat
- filefd
- filesystem
- xfs
- systemd
- uname
- time
- os
- stat
- loadavg
- sockstat
- netclass- 重载 prometheus 服务
curl -X POST http://127.0.0.1:9090/-/reload- 查看收集的指标
minio_health_check
- 配置告警规则,检测过去5分钟内是否存在健康检查失败的状态,若存在则触发告警
avg_over_time(minio_health_check[5m]) == 0二、使用 Grafana 绘制 MinIO 监控大屏
2.1 先决条件:
- 现有的 Prometheus 部署,并支持 警报管理器
- 现有的 MinIO 部署,可以与 Prometheus 部署建立网络连接
- 已安装的 Grafana
2.2 Grafana 模板
MinIO 提供了多个官方 Grafana 仪表板,可以从 Grafana 仪表板门户网站下载。
直接导入模板 id,json 文件;然后微调变量即可。
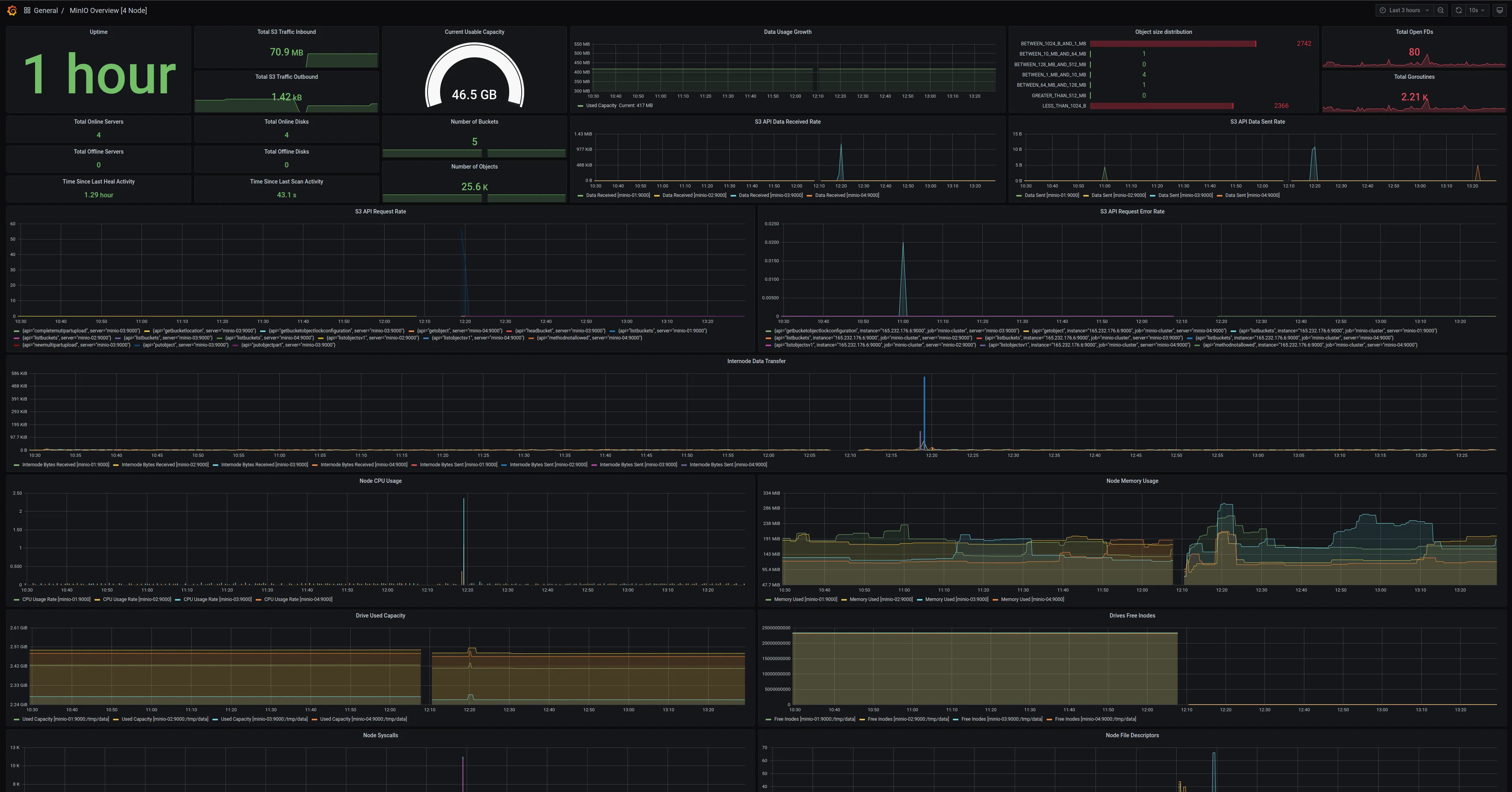
- MinIO 服务器指标仪表板,模板 id:
13502
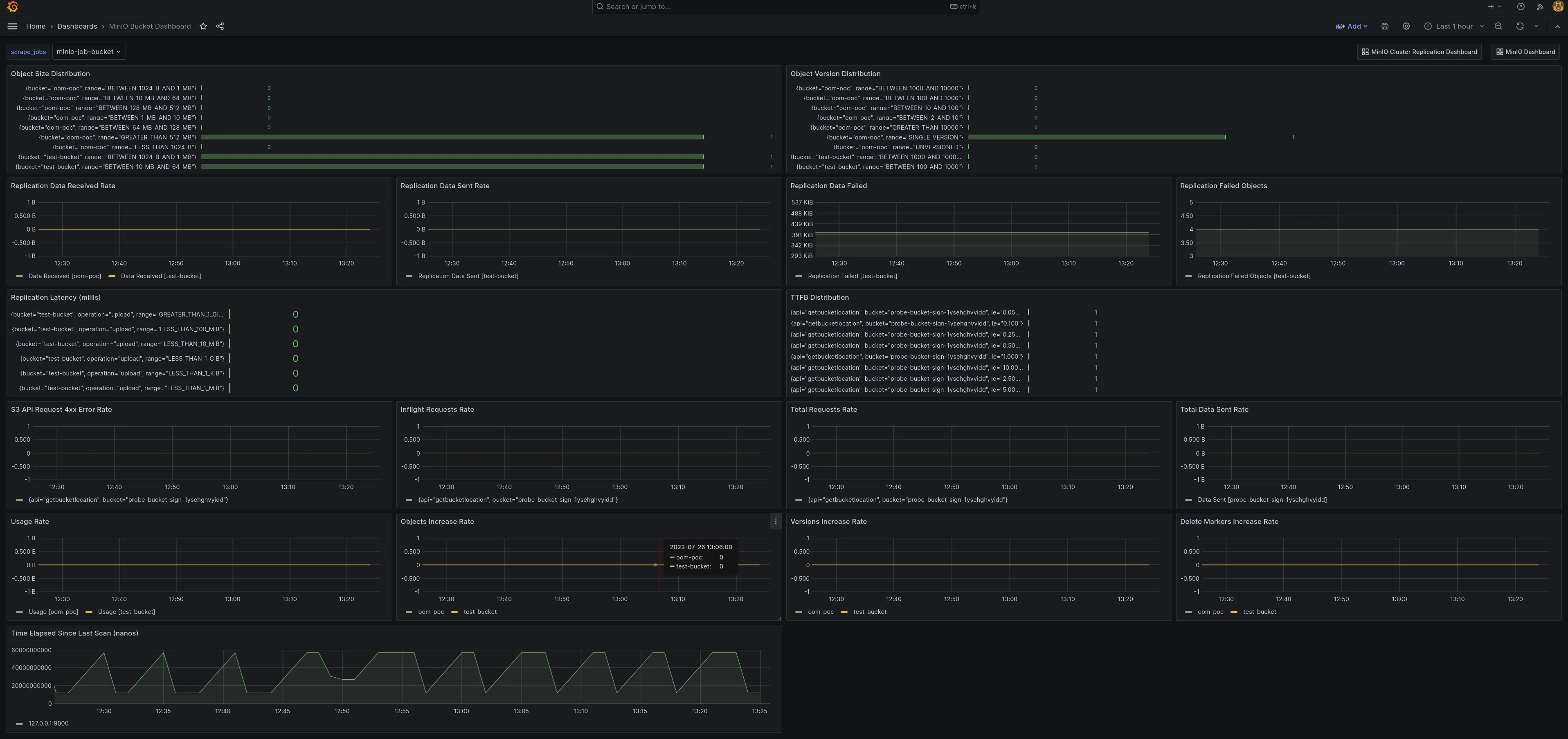
- MinIO 存储桶指标仪表板,模板 id:
19237
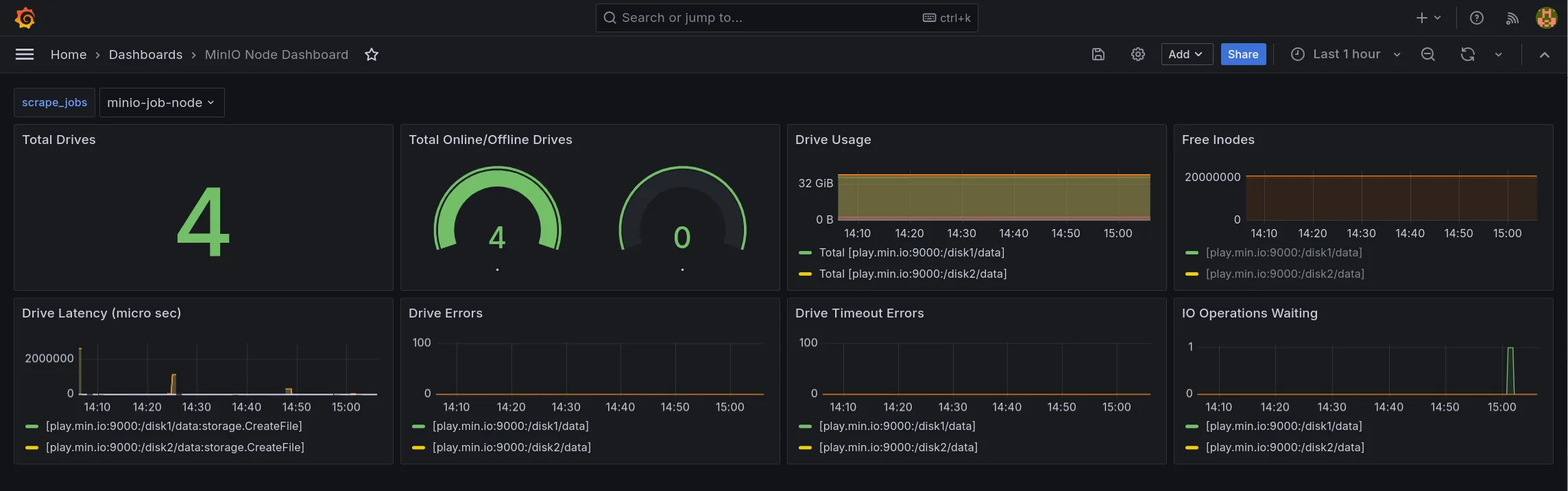
- MinIO 节点指标仪表板,json 文件
https://raw.githubusercontent.com/minio/minio/master/docs/metrics/prometheus/grafana/node/minio-node.json
三、参考
- https://min-io.cn/docs/minio/kubernetes/upstream/operations/monitoring.html
- https://grafana.com/grafana/dashboards/13502-minio-dashboard/
- https://grafana.com/grafana/dashboards/19237-minio-bucket-dashboard/
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 运维小弟
